Was fehlt: „Alle 3 Stunden abrufen“ für Instant Messenger
Am Anfang war das ganz normal: E-Mails hat der Mailclient per POP3 abgeholt. Und zwar per Polling, in einem definierten Intervall. Natürlich geht das inzwischen in Echtzeit, per IMAP oder anderen Push-Protokollen.
Auf meinem Telefon bin ich aber wieder zu dem alten Muster „Alle 3 Stunden abrufen“ zurück. Ich möchte keine Echtzeit- Unterbrechung von jeder E-Mail. Alle paar Stunden gesammelt die neuen Mails angezeigt zu bekommen ist perfekt.
Instant Messenger haben sich auf eine andere UX geeinigt, falls du deine Push-Notifications in den Griff bekommen möchtest. „Stummschalten für 1 Stunde / für 8 Stunden / für immer“. Das ist schade. Ich will ja Benachrichtigungen über Aktivität in diesem Chat bekommen. Nur nicht sofort für jede Nachricht.
„Alle 3 Stunden abrufen“, ich will dich zurück!
The simple power of Docker Multi-Stage builds
Ever needed to combine multiple Docker images? Public images from the Docker Hub are mostly
good at exactly one thing. But often your application consists of multiple technologies. You have a Java backend, but also
need NodeJS to transpile and bundle your TypeScript frontend? If you use a full CI/CD environment, like on GitLab or GitHub,
you can run multiple tasks and assembly the artifacts into a final image. But that is a big step up from the simplicity of a
single Dockerfile.
- you cannot run the build locally anymore
- you cannot easily use a
git pushdeployment anymore, with the convenient GitOps hosters, like Fly.io, Heroku, or Dokku, which work from a single Dockerfile directly from a git repository
This is where Docker Multi-Stage builds really shine.
Example Dockerfile
# Run frontend build in a temporary node image: FROM node:22 AS builder COPY . /tmp/app WORKDIR /tmp/app/ui RUN npm ci RUN npm run build # Create the actual application image: FROM python:3.11 COPY --from=ghcr.io/astral-sh/uv:latest /uv /bin/uv WORKDIR /usr/src/app COPY . . # Install dependencies RUN uv sync # Fetch the frontend build artifacts from the builder image stage COPY --from=builder /tmp/app/static ./static EXPOSE 5000 CMD [ "uv", "run", "gunicorn", "server:app", "--bind", "0.0.0.0:5000"]
Benefits
This build produces 1 single docker image, but during the build, it relies on 3 different images:
- The
nodeimage is used to create a throw-away container in which we run the frontend build - We need a binary from the official image released for the
uvpackage manager (this is much more convenient than somewgetandtar -xzvfcombination) - Finally, we want the
pythonimage as the base for our application
The core elements are multiple FROM statements to introduce multiple stages, and COPY --from to
access results from these other stages.
By using Docker Multi-Stage builds, you can keep your setup simple while leveraging the full power of multiple environments in a single image.
37C3 – meine Favoriten vom Chaos Communication Congress
 Der 37C3 war meine bisher längste und intensivste Congress-Teilnahme. Ein tolles Umfeld, freundliche Leute und wahnsinnig viel Input. Das hier sind die Talks, die hängen geblieben sind und die es sich lohnt, per Video nachzuholen.
Der 37C3 war meine bisher längste und intensivste Congress-Teilnahme. Ein tolles Umfeld, freundliche Leute und wahnsinnig viel Input. Das hier sind die Talks, die hängen geblieben sind und die es sich lohnt, per Video nachzuholen.
Toniebox Reverse Engineering
Eine umfassende Übersicht über Hardware und Software der Kinder-Audio-Box. Komplettes Reverse Engineering.
Kurz gefasst:
- Lob für die robuste und wartbare Hardware
- Das Teil sendet sehr umfassende Telemetrie bei jeglicher Interaktion, wer das nicht möchte kann den Host
rtnl.bxcl.deblocken (z.B. im Router), dann kommt nichts mehr zum Hersteller durch
How to build a submarine and survive
Inspirierender Vortrag über ein DIY-Sporttauchboot, gebaut von leicht verrückten, aber sehr sorgfältig vorgehenden Hackern.
Decentralized energy production: green future or cybersecurity nightmare?
Kleine PV-Anlagen und Balkonkraftwerke haben gerne eine dazugehörige App für Steuerung und Monitoring. Was wäre, wenn führende Anbieter bei der Implementierung der Software eine Reihe von handwerklichen Fehlern gemacht hätten, die die komplette Übernahme von Hunderttausenden Installationen erlauben?
TL;DR: In der IT-Security zählt jedes Detail.
Digital clock challenge - Answers (Part 2)
Working on the Digital clock challenge, we've previously established in Part 1, that after recording 121 minutes of brightness levels emitted from a digital clock with a 7-segment display, we can tell the time!
But now let's revisit a more difficult version of this: if we start staring at a wall illuminated by that clock, we don't get absolute brightness levels, but rather only the relative changes from one minute to another. This would probably make it more ambiguous to identify the current point in time. Is it still possible? Let's find out.
Adapt the program
It takes some small adjustment to make the Python script from Part 1 to work with relative instead of absolute values. We generate those delta values from the absolute values of a full day:
def get_deltas(data): """ Calculate the deltas (differences) from a given list of numbers. >>> get_deltas([0, 1, 1, 2, 1]) [1, 0, 1, -1] >>> get_deltas([0]) [] """ deltas = [] for index, _ in enumerate(data): if index + 1 < len(data): deltas.append(data[index + 1] - data[index]) return deltas
And now we can use that in our main function:
if __name__ == "__main__": import doctest logging.basicConfig(level=logging.ERROR, format="%(message)s") doctest.testmod() logging.getLogger().setLevel(logging.INFO) # Generate segment count for all minutes of the day all_times = all_times() # And now the relative changes from minute to minute deltas = get_deltas(all_times) # Increase length of observed minutes window, until we get an # unambiguously identified time for i in range(24 * 60): logging.info("Testing if window size of %i minutes is unique." % i) windows = get_windows(deltas, i) if has_unique_elements(windows): logging.info("Windows of size %i provide unique combinations." % i) break
It is still enough
When running it, we quickly get a conclusion:
Windows of size 600 provide unique combinations.
So, if we observe 600 minutes (10 hours!) of brightness changes caused by the changes of the clock numbers, we can deduce which time it is!
That sounds absurdly long. Of 1440 minutes in a day, we need to wait 600 minutes in order to find a truly unique sequence of changes?
Why so long?
If you think about the inherent order that is present in those values
it makes sense. The changes of the 2 digits that represent the minutes, from :00 to :59 repeat every hour,
so any sequence below 60 minutes will be present at least 24 times during the day. We need to rely on the hour
digits in order to form a unique sequence. And they don't change very often (well, once per hour), so now it makes
sense that we need to make the time window quite long in order to ensure a unique sequence of changes. And it is not
by accident that the result, 600 minutes, is a whole-number of hours.
Digital clock challenge - Answers (Part 1)
I've worked on the Digital clock challenge, evaluating the initial and basic questions:
- is it theoretically possible to tell the time, just by looking at the level of light sent out by the clock?
- how long would you need to stare at the wall? 2 minutes? 20 minutes? Even hours?
These questions boil down to one: is a sequence of different brightness levels (changing each minute) so unique that it can be traced back to a specific time on the clock? Surely, looking a 1 minute only is not enough. The number of illuminated clock segments only goes from 8 to 26 - but there are 24 * 60 = 1440 minutes in a day.
So, let's write a program that
- generates the segment count for the sequence of all 1440 minutes in a day
- check how long we need to make a subset of this sequence in order to uniquely identify this subset in the full set
The Python script that gives us the answer
Here's what I ended up with in Python:
#!/usr/bin/env python import logging from datetime import time, timedelta, datetime, date def digit_to_segment_count(digit): """ Take a single digit and return the number of "on" segments for it. """ SEGMENTS = [ 6, # 0 2, # 1 5, # 2 5, # 3 4, # 4 5, # 5 6, # 6 3, # 7 7, # 8 6, # 9 ] return SEGMENTS[digit] def time_to_segment_count(time): """ Return the total number of "on" segments of a (simple) time with 4 digits. >>> time_to_segment_count(time.fromisoformat("00:00")) 24 >>> time_to_segment_count(time.fromisoformat("11:11")) 8 """ sum = 0 sum += digit_to_segment_count(int(str(time)[0])) sum += digit_to_segment_count(int(str(time)[1])) sum += digit_to_segment_count(int(str(time)[3])) sum += digit_to_segment_count(int(str(time)[4])) return sum def all_times(): """ Generate all existing times from 00:00 to 23:59 and return their segment count. >>> times = all_times() >>> len(times) == 24 * 60 True >>> times[0] == 6 + 6 + 6 + 6 # 00:00 segment count True >>> times[-1] == 5 + 5 + 5 + 6 # 23:59 segment count True """ all_times = [] current_time = time.fromisoformat("00:00") for i in range(0, 24 * 60): all_times.append(time_to_segment_count(current_time)) current_time = ( datetime.combine(date.today(), current_time) + timedelta(minutes=1) ).time() return all_times def get_windows(data, window_size): """ Given a list of n elements, generate n tuples with a given length. >>> data = [0, 1, 2, 3, 4] >>> get_windows(data, 1) [(0,), (1,), (2,), (3,), (4,)] >>> get_windows(data, 2) [(0, 1), (1, 2), (2, 3), (3, 4), (4,)] """ windows = [] for i, _ in enumerate(data): start = i end = i + window_size windows.append(tuple(data[start:end])) return windows def has_unique_elements(data): """ Check if a given list has only unique elements. This is used to check if a given sequence of brightness levels designates a specific time unambiguously. >>> has_unique_elements([0, 1, 2]) True >>> has_unique_elements([1, 0, 1]) False >>> has_unique_elements([(0,1), (1,2), (2,3)]) True >>> has_unique_elements([(0,1), (1,2), (0,1)]) False """ duplicate_count = len(data) - len(set(data)) logging.info("%i duplicates found" % duplicate_count) return duplicate_count == 0 if __name__ == "__main__": import doctest logging.basicConfig(level=logging.ERROR, format="%(message)s") doctest.testmod() logging.getLogger().setLevel(logging.INFO) # Generate segment count for all minutes of the day all_times = all_times() logging.info("Highest number of segments: %i" % max(all_times)) logging.info("Lowest number of segments: %i" % min(all_times)) # Increase length of observed minutes window, until we get an # unambiguously identified time for i in range(500): logging.info("Testing if window size of %i minutes is unique." % i) windows = get_windows(all_times, i) if has_unique_elements(windows): logging.info("Windows of size %i provide unique combinations." % i) break
The result: it will work
So, let's run it:
Highest number of segments: 26
Lowest number of segments: 8
Testing if window size of 0 minutes is unique.
1439 duplicates found
Testing if window size of 1 minutes is unique.
1421 duplicates found
Testing if window size of 2 minutes is unique.
1330 duplicates found
Testing if window size of 3 minutes is unique.
1216 duplicates found
Testing if window size of 4 minutes is unique.
1147 duplicates found
Testing if window size of 5 minutes is unique.
1096 duplicates found
[...]
Testing if window size of 119 minutes is unique.
4 duplicates found
Testing if window size of 120 minutes is unique.
2 duplicates found
Testing if window size of 121 minutes is unique.
0 duplicates found
Windows of size 121 provide unique combinations.
If we observe the digital clock brightness levels (as count of illuminated segments) for 121 minutes, this sequence of values is unique within the 24h of the day and thus enables us to tell the current time.
Small known issue: midnight
I could not yet be bothered to take a special case into account: if the observed time wraps around over midnight.
The digital clock segment brightness challenge
It is the middle of the night. You are sitting in your kitchen. The only source of light is the digital clock on your oven, telling the time with 4 bright digits. But the clock is behind you, so you cannot see it. You can only see the wall and furniture opposite you, weakly illuminated by the digital clock.
Every minute, the brightness of the clock light shining onto your kitchen changes slightly, as time advances. Some numbers are brighter, since they use more of the available 7 segments.
11:11 is the least bright time (8 segments are on). 88:88 would be the brightest number (28 segments), but is doesn't exist as a time. So 08:08 (26 segments) may be the brightest.
Unable to sleep, you are wondering if it is possible to actually know the time, just be looking at the diffuse brightness on the wall opposite you.
Questions
- is it theoretically possible to tell the time, just by looking at the level of light sent out by the clock?
- how long would you need to stare at the wall? 2 minutes? 20 minutes? Even hours?
- how could this be implemented as a computer program, given perfectly clean brightness levels (from 8 to 26) for each minute as input?
- how could it be done with only relative changes of brightness from one minute to another?
- how could it be done with a noisy video of the wall and furniture, with a constantly changing, auto-adjusted camera aperture?
I intend to revisit and solve the above questions whenever there is time and I feel like it.
Answers
TDD does not mean writing all the tests up-front
There is a common misconception regarding TDD (Test-driven Development) which I frequently encounter in discussions or interviews, when I ask: "Do you actually practice TDD?" Often the answer will be something like "No, I cover my code with tests later. It is unrealistic to write all the tests first, who even does that?"
And they are right. Of course it is completely unrealistic to write all the tests first, like this:

It would require you to have a complete mental model of all the units of code you are going to write, all interfaces, classes, functions. And that goes against the core agile idea of working iteratively, step by step.
But this is an incorrect understanding of TDD. "Driven" by tests does not mean having all tests done first. It just means that tests are driving you alongside with the implementation.
Robert C. Martin says it best in The Three Laws of TDD:
Over the years I have come to describe Test Driven Development in terms of three simple rules. They are:
- You are not allowed to write any production code unless it is to make a failing unit test pass.
- You are not allowed to write any more of a unit test than is sufficient to fail; and compilation failures are failures.
- You are not allowed to write any more production code than is sufficient to pass the one failing unit test.
So this means that you keep switching between tests and implementation constantly, looking more like this:

Yes, you write the test case just slightly in advance of the implementation, but only a tiny piece of it. This way, you are clearly not required to have a full mental model of your code design. You can explore your API step by step, truly "driven" by the test cases. If you need an example of how this can work, read Engineer Notebook: An Extreme Programming Episode.
Impfnachweis-App: Eine Ideenskizze
Die Covid-19 Warn- und Tracing-Apps waren und sind heiß diskutiert. Die CWA war aufwändig und teuer, hat aber viel Lob bekommen. Die Luca-Tracing-App ist auch sehr teuer und hat vernichtende Kritik einstecken müssen (z.B. bei Logbuch Netzpolitik), weil Design und Implementierung fundamentale Fehler vorgeworfen wurden.
Der aktuell diskutierte nächste Schritt in der Pandemie sind Lockerungen für geimpfte (oder auch frisch getestete) Personen. Es stellt sich sofort die Frage, wie „geimpft sein“ nachzuweisen geht. Der klassische gelbe Papier-Impfpass ist recht anfällig für Fälschungen und auch eher unhandlich.
Eine Impfnachweis-App ist wohl in Arbeit (Bundesgesundheitsministerium). IBM ist beteiligt, ausgerollt werden soll sie laut Presseberichten vielleicht als Teil der CWA. Technische Details sind noch keine bekannt, irgendwas mit „Impfbescheinigungstoken (2D-Barcode) “
Zeit für eine Fingerübung: Welche Anforderungen und Abwägungen sind für mich bei so einer Impfnachweis-App relevant und wie würde ich eine Lösung angehen?
Anforderungen
Must-have-Eigenschaften
Ein Impfer oder Tester kann einen digital signierten Nachweis für eine erfolgte Impfung oder einen negativen Test ausstellen.
Dieser Nachweis muss durch einen Prüfer schnell und auch offline mit einem gängigen Endgerät gescannt und validiert werden können.
Zusätzlich muss online validiert werden können, ob der ausgestellte Nachweis eventuell widerrufen wurde oder sogar der Impfer/Tester komplett als unzuverlässig widerrufen wurde.
Bei dem Scan zur Validierung sind keine persönlichen Daten der Person auslesbar und sammelbar (Name, Geburtsdatum).
Stichprobenartig kann vom Prüfer validiert werden, dass der Nachweis zu einem zusätzlich vorgelegten amtlichen Ausweis passt, anhand von Name und Geburtsdatum.
Unvermeidbare, akzeptable Eigenschaften
Ein Prüfer (oder eine zusammenarbeitende Gruppe von Prüfern) kann Gruppen von Benutzern identifizieren, die vom selben Impfer/Tester einen Nachweis ausgestellt bekommen haben (anhand einer Impfer-ID o.ä).
Ein Prüfer (oder eine zusammenarbeitende Gruppe von Prüfern) kann wiederholte Scans des gleichen Nachweises beobachten, daher theoretisch daraus Bewegungsprofile (anhand einer Nachweis-ID o.ä.) erstellen.
Wünschenswerte Eigenschaften
Der Nachweis ist per Scan nicht eindeutig identifizierbar, Bewegungsprofile vermeiden.
Prinzipien und Abwägungen
Anders als bei der CWA haben die Benutzer_innen der Impfnachweis-App kein Interesse daran, die eigene Identität „sauber“ abzubilden. Es macht keinen Sinn, die CWA auf dem Smartphone des Mitbewohners mit zum Brötchen holen zu nehmen - denn dann bekommt jener eventuell eine Warnung zu einer Risikobegegnung, die er gar nicht selbst hatte. Er war ja schließlich gar nicht neben dem Infizierten in der Bäckerei.
Wenn mein Mitbewohner aber geimpft ist, und ich durch Vorzeigen seines Handys Einlass in die Bäckerei bekommen kann, ist es naheliegend, diese andere Identität vorzutäuschen. Anders als bei der Kontaktverfolgung der CWA kann die Impfnachweis-App also nicht anonymisiert funktionieren, sondern muss an irgendeiner Stelle mit einer „offiziellen“ Identität verknüpft sein, damit ein Prüfer sicherstellen kann, dass der vorgelegte Nachweis auch zur vorzeigenden Person gehört.
Gleichzeitig sind jedoch Datenschutz und Anonymität wünschenswert. Ein einzelner, oder sogar eine Vielzahl von kooperierenden Prüfern soll kein Bewegungsprofil von Benutzern erstellen können, oder eine Liste aller Gäste einer Einrichtung anfertigen können.
Diese Ziele stehen grundsätzlich im Widerspruch zueinander. Dieser Widerspruch kann nur abgemildert werden.
Abgleich mit der „offiziellen“ Identität nur stichprobenartig
Für den Prüfer ist nur ein stichprobenartiger Abgleich der Identität vorgesehen. Bei diesem Abgleich fällt ein gewisser manueller Aufwand an: Der Prüfer muss den Benutzer auffordern, die persönlichen Daten in der App freizugeben und diese zum Abgleich mit dem signierten Nachweis auch abtippen. Dadurch wird die massenweise Erhebung aller geprüften persönlichen Daten zumindest ökonomisch unattraktiv. Wenn die Stichproben häufig genug stattfinden, wird gleichzeitig das Risiko, die Daten einer anderen Person vorzuzeigen, ebenso unattraktiv hoch.
Bewegungsprofile erschweren
Die Bildung von Profilen anhand der gescannten Nachweise wird dadurch erschwert, dass jeder Benutzer eine Vielzahl von Nachweisen erhält (Hunderte) und die App zufallsgesteuert dem Prüfer nur einen der Nachweise anzeigt. Somit wird jegliches Profil immer lückenhaft sein, selbst wenn z.B. ein Dienstleister alle Einlasskontrollen in einer ganzen Stadt durchführt und versucht, Bewegungsprofile zu erstellen.
Abgrenzungen
Es gibt keine zentrale Datenhaltung. Der Nachweis ist das digitale Pendant zum gelben Impfpass. Bei Verlust (der Daten oder des Gerätes) muss der Benutzer einen neuen Nachweis vom Impfer/Prüfer erhalten. Eine persönliche Sicherheitskopie oder eine dezentrale Sicherheitskopie des Impfers von allen ausgestellten Nachweisen ist hier out of scope.
Offline-Tauglichkeit
Sowohl Benutzer_innen als auch Prüfer können offline arbeiten. Für die Prüfung der Signatur des Nachweises ist keine Serververbindung notwendig. Eine Sperrliste von widerrufenen Nachweisen oder Impfern sollte bei jedem Prüfer in der App möglichst aktuell vorliegen, für die Validierung selbst ist aber keine bestehende Verbindung notwendig.
Solution Outline
So könnte ein Design grob funktionieren:
Daten auf dem Nachweis
- Immunität ab/bis (Eintritt der ausreichenden Impfwirkung, bzw. Ablauf der Gültigkeit des Testergebnisses)
- [Prüfkennung (Salt)]
- [Vorname + Nachname]
- [Geburtsdatum]
- Hash über persönliche Daten plus Salt (2. + 3. + 4.)
- Signatur von 1. und 5. durch den Impfer
- Public Key der Impfers
- Signatur von 7. durch Root CA
Die mit [] gekennzeichneten Daten sind nicht technisch per QR-Code auslesbar, sondern nur visuell als Text. Alle anderen Informationen sind als QR-Code auslesbar.
Operationen
Diese Schritte sind im Prozess zentral:
1) Ausstellen des Belegs
Impfer/Tester prüft einen aktuellen Ausweis und gibt Name, Vorname + Geburtsdatum (Daten 3. + 4.) in die App ein. Die App randomisiert eine Prüfkennung (2.), die leicht abzutippen ist, aber ausreichend Entropie hat, um als Salt zu dienen, z.B. "ab37p". Über persönliche Daten und Salt wird ein Hashwert (5.) generiert. Der Gültigkeitszeitraum Immunität (1.) wird je nach Vorgang (Test oder Impfung) vorbelegt. Der Prüfer signiert den Hash und die Immunitätsdaten mit seinem Private Key, der wiederum selbst von einer zentralen Stelle (Root CA) ausgestellt und unterschrieben wurde. Der Public Key wird ebenfalls in den Nachweis integriert, damit er bei einem Prüfung offline vorliegt.
Von diesem Nachweis werden vom Impfer/Tester (automatisiert) mehrere hundert Exemplare ausgestellt, immer mit anderen Prüfkennungen, und somit auch anderen Hash- und Signaturwerten (5. und 6.).
Alle Exemplare des Nachweises werden nun in die App des Benutzers übertragen.
2) Scan-Prüfung des Nachweises
Der Benutzer zeigt dem Prüfer die App vor, welche einen zufällig ausgewählten Nachweis als QR-Code anzeigt. Die Prüfer-App validiert, ob die Gültigkeit der Immunität heute zutrifft und ob die Signatur (6.) von Gültigkeit und Hash zum Public Key des Impfers/Testers (7.) passt. Außerdem prüft sie, ob der Public Key auch korrekt von der Root CA signiert wurde, es sich also um einen offiziellen Impfer/Tester handelt.
Damit ist sichergestellt, dass der vorgezeigte Nachweis heute gültig ist und von einem offiziellen Impfer/Tester ausgestellt wurde.
3) Optionale Prüfung auf Nicht-Widerruf
Die Prüfer-App gleicht anschließend ab, ob der Nachweis (identifiziert durch die Signatur 6.) oder sogar der Impfer/Prüfer (identifiziert durch dessen Public Key) als Fälschung oder unzuverlässig auf einer Sperrliste stehen. Diese Sperrliste wird regelmäßig vom Server der Root CA heruntergeladen.
Damit ist sichergestellt, dass der vorgezeigte Nachweis nicht inzwischen als ungültig erklärt wurde.
4) Stichprobenartige Prüfung der Identität
Die Prüfer-App löst in 5-10% der Validierungen eine Identitätsprüfung aus, um sicherzustellen, dass der Nachweis auch wirklich zum Benutzer gehört. Hierzu legt der Benutzer in der App einen vorher versteckten Bereich „Prüfdaten“ frei. Dieser zeigt die nicht im QR-Code enthaltenen Daten (2. + 3. +4.) in Textform an: Prüfkennung, Vorname/Nachname und Geburtsdatum. Der Prüfer tippt diese Informationen in die Prüfer-App ein und vergleicht sie mit einem offiziellen Ausweisdokument. Die Prüfer-App berechnet den Hash über die eingegebenen persönlichen Daten und vergleicht ihn mit dem eingescannten Hashwert aus dem Nachweis.
Damit ist sichergestellt, dass der vorgezeigte Nachweis auch wirklich zum offiziellen Ausweis und damit zur Person passt.
(Die Prüfkennung/Salt soll verhindern, dass in einer großen Menge erfasster Scans gezielt nach einer Person anhand des berechenbaren Hashwertes von Vorname/Nachname + Geburtsdatum gesucht werden kann. Durch die zufällige Prüfkennung wird dieser Hashwert unvorhersehbar und muss für jeden erfassten Scan einzeln nachberechnet werden.)
Offene Fragen
- Welche Digitalen Signaturalgorithmen (DSA) eignen sich? Irgendwas mit Elliptic Curve?
- Passen die genannten Daten überhaupt in einen QR-Code? iQR-Code? JAB Code?
- Auf welchem Transportweg werden die vom Impfer/Tester erstellten Nachweise schnell in die App des Benutzers übertragen? Ist per QR-Scan schnell genug?
- Welche Schlüssel-/Signaturlängen sind zu wählen, welche Hashfunktion mit wie vielen Iterationen ist zu wählen, um die gewünschte Sicherheit zu erhalten?
Datenmenge und Kapazität
Mit grob recherchierten Algorithmen:
| Element | Typ | Größe |
|---|---|---|
| 1. Immunität ab/bis | 2x Unix timestamp | 64 bit = 8 bytes |
| 5. Hash | SHA3-256 | 256 bit = 32 bytes |
| 6. Signatur (Impfer) | ECDSA Signature | 72 bytes |
| 7. Public Key | ECDSA Public key | 256 bit = 32 bytes |
| 8. Signatur (Root) | ECDSA Signature | 72 bytes |
| Summe: | 1728 bit / 216 bytes |
Diese Datenmenge ist im Rahmen eines normalen QR-Codes.
Traffic Pilot – die Grüne-Welle-App getestet in Düsseldorf
Irgendwann im Testbetrieb war mir „traffic pilot“ schon mal aufgefallen, damals aber nur mit ein paar Hauptstraßen, also nicht wirklich nutzbar. Inzwischen ist die App aber im ganzen Düsseldorfer Stadtgebiet verfügbar. Zeit für einen Test auf dem Fahrrad.

Funktionen
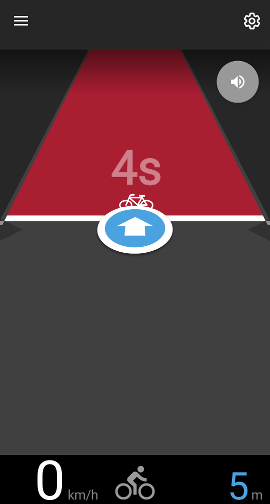
Die Kernfunktion ist einfach: Die App zeigt mir an, ob ich die nächste Ampel bei „grün“ oder bei „rot“ erreichen werde, bzw. ob ich schneller oder langsamer fahren sollte, um eine grüne Welle sicher zu stellen. Die Oberfläche ist sehr funktional, eine perspektivische Straßenansicht zeigt, ob ich im grünen oder roten Bereich unterwegs bin. Wenn ich vor der roten Ampel stehen bleibe, bekomme ich die verbleibende Zeit der Rotphase in Sekunden heruntergezählt.
Funktioniert es denn?
Auf dem Fahrrad hält die App tatsächlich ihr Versprechen. Nach ein paar Metern Fahrt wird die nächste voraus liegende Ampel identifiziert und die Entfernung angezeigt. Die Oberfläche zeigt wie geplant die roten und grünen Markierungen an.
Für Kreuzungen mit mehreren Ampeln (z.B. für mehrere Spuren) gibt es eine pragmatische Lösung, um die Informationen für alle Spuren anzuzeigen, schließlich weiß die App nicht, ob ich abbiegen möchte.

Schwächen
Das größte Manko ist, dass eben doch nicht alle Ampeln integriert sind (Alle Standorte gibt es beim Betreiber). Manchmal hat die App schon die übernächste Ampel angezeigt, sodass ich mich abgestrampelt habe, um diese noch bei Grün zu erreichen – um dann festzustellen, dass die nächste Ampel gar nicht abgebildet wird und natürlich Rot ist.
Ansonsten sind die Angaben eben doch nicht ganz genau. Und fünf Sekunden Verzögerung können ärgerlich sein, wenn ich mit Hilfe der App doch die perfekte Grüne Welle ohne Abbremsen hinbekommen wollte.
Nutzen
Auf dem Fahrrad habe ich schnell gemerkt: Mein Einfluss auf das Erreichen der nächstem Ampelphase ist sehr begrenzt. Der nötige Energieeinsatz ist den Zeitgewinn meist nicht wert. Umso mehr, wenn eine ungenaue Anzeige den Sprint dann noch zunichte macht.
Mein Lieblingsfeature hat mit der grünen Welle gar nichts zu tun: Es ist die Anzeige der restlichen Rotphase. Nicht die Ampel hypnotisieren zu müssen, sondern entspannt 30 Sekunden in die Gegend zu schauen, ist sehr nett.
Und im Auto? Ganz ehrlich: Wer vorausschauend fahren möchte, kann das. Auch ohne App. Wenn die Ampelphasen vielleicht irgendwann mal in einen adaptiven Tempomaten einfließen, wird es vielleicht interessant.
Also: Respekt für das technische Projekt, ein alltäglicher Nutzen überwiegt noch nicht. Als Randnotiz ist noch eine vorbildliche Datenschutzerklärung zu nennen. Eine knappe aber klare Erklärung stellt klar, welche Daten übertragen werden. Als User werde ich über eine pseudonymisierte ID identifiziert, die regelmäßig wechselt.
Pünktlich Segeln - Wie lange muss ich motoren?
Du bist auf einem Segelboot und hast ein festes Ziel, das du bis zu einer bestimmten Uhrzeit erreichen musst. Unter Segeln bist du nicht schnell genug, um es pünktlich zu schaffen, daher weißt du schon, dass du ein Stück unter Motor fahren musst. Als ehrgeiziger Segler möchtest du diese Zeit aber möglichst kurz halten.
Wie lässt sich diese Zeit berechnen? Zeit für eine Runde Schulmathematik.
Wir nehmen als Ausgangspunkt das Weg-Zeit-Gesetz: $$d = V \cdot t$$ Die zurückgelegte Strecke \(d\) entspricht der Geschwindigkeit \(V\) mal der Zeit \(t\). Wir haben allerdings zwei verschiedene Geschwindigkeiten und Zeiten, jeweils Segel und Motor: $$d = V_s \cdot t_s + V_m \cdot t_m$$ Die Segelzeit ist der Rest der Gesamtzeit abzüglich der Motorzeit, also können wir das einsetzen. $$d = V_s \cdot t_s + V_m \cdot t_m \quad | t_s = t - t_m$$ $$d = V_s \cdot (t - t_m) + V_m \cdot t_m$$ und anschließend umstellen, um \(t_m\) zu erhalten, nämlich die Motorzeit, die uns ja interessiert. $$d = V_s \cdot t - V_s \cdot t_m + V_m \cdot t_m$$ $$d = -V_s \cdot t_m + V_m \cdot t_m + V_s \cdot t$$ $$d = t_m \cdot (V_m - V_s) + V_s \cdot t \quad | - V_s \cdot t$$ $$d - V_s \cdot t = t_m \cdot (V_m - V_s) \quad | : (V_m - V_s)$$ $$t_m = \frac{d - V_s \cdot t}{V_m - V_s}$$ Das macht auch plötzlich Sinn: Über dem Bruchstrich steht die Strecke, die noch übrig bleiben würde, wenn wir die ganze verfügbare Zeit nur mit Segelgeschwindigkeit fahren. Diese Strecke „fehlt“ uns und wir müssen sie durch die höhere Motorgeschwindigkeit ausgleichen. Diese Geschwindigkeitsdifferenz steht unter dem Bruchstrich und beantwortet dann die Frage, wie lange wir denn diese Geschwindigkeitsdifferenz anwenden müssen - also eben das gesuchte \(t_m\)
In Worten: Rechne aus, wie weit du rein unter Segeln in der verfügbaren Zeit kommst. Die verbleibende Strecke teilst du durch den Geschwindigkeitsvorteil, den der Motor bringt. Dann weißt du, wie viel Zeit du motoren musst, um die gesamte Strecke in der verfügbaren Zeit zu schaffen.